In the world of data engineering, managing workflows that process vast amounts of data reliably and efficiently is critical. As datasets grow in complexity, traditional approaches often face limitations in scalability, resource management, and collaboration. Enter Kubeflow, an open-source machine learning (ML) toolkit built on top of Kubernetes. While Kubeflow was initially designed for ML workloads, it also offers powerful tools for data engineering, making it a great solution for building scalable, flexible, and highly efficient data pipelines.
In this blog, we’ll explore how to leverage Kubeflow on Kubernetes for a real-world data engineering use case. We’ll cover the architecture, the benefits, and how to get started with a basic pipeline.
Why Use ?
Before diving into the technical details, let’s quickly cover why Kubeflow is a great option for data engineering tasks:
- Scalability: Kubeflow takes advantage of Kubernetes’ inherent scalability, making it easier to scale pipelines horizontally and handle high volumes of data with minimal manual intervention.
- Automation & Orchestration: Using Kubeflow Pipelines, you can automate and orchestrate complex data workflows, ensuring reproducibility and consistent execution.
- Resource Management: Kubernetes’ resource management (CPU, GPU, memory) is a perfect fit for optimizing the performance of data engineering tasks, balancing workloads efficiently across available resources.
- Flexibility: You can run heterogeneous workloads (like ETL, data preprocessing, machine learning model training, etc.) all within the same environment, reducing overhead from multiple systems.
- Reusability: Modular components in Kubeflow enable you to easily reuse parts of a pipeline in different workflows, saving time and effort.
Use Case: Building a Scalable Data Ingestion and Processing Pipeline
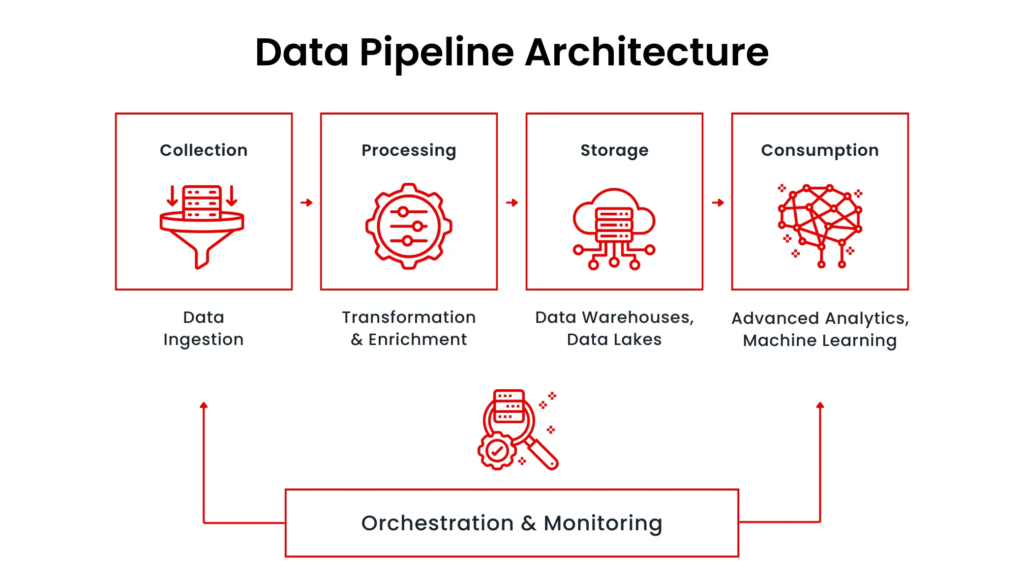
Let’s assume we’re working on a data ingestion and processing pipeline for an e-commerce platform. The pipeline’s goal is to:
- Ingest data from multiple sources (e.g., transaction logs, user activity, inventory systems).
- Perform preprocessing, including filtering, transformation, and aggregation.
- Load the processed data into a data warehouse for analytics or into a feature store for ML purposes.
Architecture Overview
Data Sources: The raw data could come from several sources like Apache Kafka, REST APIs, or data lakes (e.g., Amazon S3, Google Cloud Storage).
Data Ingestion: Using Kubeflow Pipelines, we’ll orchestrate the ingestion of this raw data into the pipeline.
Data Processing: Once ingested, various transformations and aggregations will be performed using containerized tasks.
Data Storage: The transformed data will be stored in a data warehouse like Google BigQuery, Snowflake, or Amazon Redshift, or in a feature store for machine learning models.
Components in Kubeflow
- Kubeflow Pipelines: The backbone of our data pipeline, responsible for defining, scheduling, and monitoring the workflow.
- Argo Workflows: The execution engine for managing the pipeline tasks on Kubernetes.
- Kubernetes: Provides the underlying infrastructure for scaling and managing containerized applications and workflows.
- Persistent Storage: We can use Kubernetes Persistent Volumes (PVs) or cloud storage solutions to store intermediate and final results.
Step-by-Step: Building the
Pipeline
1. Setting Up Kubeflow on Kubernetes
First, you’ll need to install Kubeflow on your Kubernetes cluster. You can follow Kubeflow’s installation documentation for your preferred cloud provider (AWS, GCP, Azure) or a local setup using Minikube or Kind.
Once Kubeflow is up and running, you’ll access the Kubeflow dashboard, where you can manage pipelines, experiments, and workflows.
2. Designing the Data Pipeline
In Kubeflow Pipelines, you define each step of the data pipeline as an individual component. Each component is a containerized task, such as data ingestion, transformation, or loading.
Here’s a simplified version of what the pipeline might look like:
- Step 1: Ingest Data
- Use a Python-based component that pulls data from multiple sources (e.g., Kafka streams, APIs, etc.).
- This component can run in parallel, ingesting from multiple sources simultaneously.
- Step 2: Data Transformation
- Once data is ingested, it’s passed to another container that performs transformations such as cleaning, filtering, or aggregation. For example, a Spark job can run in this step using Kubernetes’ native support for distributed systems.
- Step 3: Load Data into Storage
- The final step involves loading the processed data into a warehouse or feature store. This can be done using connectors for BigQuery, Redshift, or a custom API.
Each of these steps is defined as a component in the pipeline and can run independently or be triggered sequentially.
3. Orchestrating the Pipeline with Kubeflow Pipelines
Kubeflow Pipelines uses a Python SDK to define pipelines. You’ll define each step in Python code, creating a Directed Acyclic Graph (DAG) that represents the pipeline’s execution flow.
Here’s a small snippet to give you an idea of what defining a pipeline looks like:
import kfp
from kfp import dsl
@dsl.pipeline(
name="Data Ingestion Pipeline",
description="Ingests and processes data"
)
def data_pipeline():
ingest_op = kfp.components.load_component_from_file('components/ingest.yaml')()
transform_op = kfp.components.load_component_from_file('components/transform.yaml')(ingest_op.output)
load_op = kfp.components.load_component_from_file('components/load.yaml')(transform_op.output)
if __name__ == '__main__':
kfp.Client().create_run_from_pipeline_func(data_pipeline, arguments={})
In this example, each step is defined in a YAML file for reusability, and the components can be customized as needed.
4. Monitoring and Scaling
Once your pipeline is running, you can monitor it from the Kubeflow Pipelines dashboard. You’ll see a visual representation of the DAG, where each task is monitored for completion, failure, or retries.
One of the key benefits of running on Kubernetes is that you can scale individual components based on the demand. For instance, if the ingestion step requires more resources during peak times, Kubernetes can scale that part of the pipeline without affecting other components.
5. Reusability and Versioning
Kubeflow Pipelines also allow you to reuse components across multiple pipelines, which is a huge advantage for large teams. If you’ve created a transformation component, you can easily use it in a different workflow or pipeline without having to rewrite the code.
Additionally, Kubeflow provides versioning, allowing you to track changes in pipelines over time, making it easier to iterate and improve.
Conclusion: The Power
of Kubeflow for Data Engineering
Kubeflow on Kubernetes offers an incredibly flexible and scalable solution for data engineering pipelines. Whether you’re ingesting terabytes of data or orchestrating complex workflows with numerous dependencies, Kubeflow allows you to manage everything from one unified platform.
By combining the power of Kubernetes with Kubeflow’s orchestration and automation capabilities, you can design data pipelines that are not only scalable but also efficient, modular, and easy to maintain.
If you’re looking to modernize your data engineering pipelines, adopting Kubeflow could be a game-changer for your team.
